
Now Before starting with the introduction of Data Mining, let's see the evolution of databases so that we could have an idea of how the data got stored through ages.
(Read also -> Data Mining Tasks)
Database Technology Evolution
The 1960s:- Data collection, database creation, IMS(Hierarchical), and network DBMS.
- Relational data model, relational DBMS implementation.
- RDBMS, advanced data models (extended-relational, OO, deductive, etc.).
- Application-oriented DBMS (spatial, scientific, engineering, etc.).
- Data mining, data warehousing, multimedia databases, and Web databases.
- Stream data management and mining.
- Data mining and its applications.
- Web technology (XML, data integration) and global information systems.
This information or knowledge further can be used for various applications such as market analysis, fraud detection, customer retention, production control, science exploration, etc.
Data mining
Data mining (knowledge discovery from data) is extracting or “mining” knowledge from a large amount of data.Data Mining is the preliminary process of creating a machine learning model.
Extraction of interesting (non-trivial, implicit, previously unknown and potentially useful) patterns or knowledge from the huge amount of data.
A few of its alternative names are Knowledge Discovery (mining) in Databases (KDD), Knowledge Extraction, Data/Pattern Analysis, Data Archeology, Data Dredging, Information Harvesting, Business Intelligence, etc.
Knowledge Discovery Process
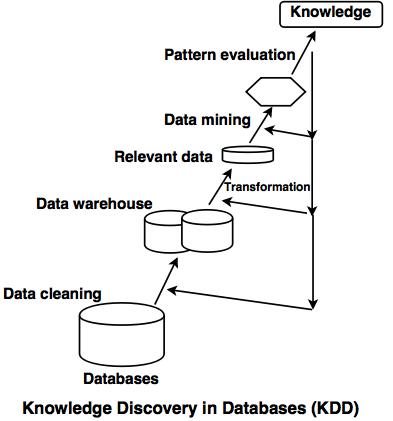
Data Cleaning: to remove noisy and inconsistent data.
Data integration: where multiple data sources may be combined and integrated.
Data selection: where data relevant to the analysis tasks are retrieved from the databases.
Data transformation: where data is transformed and consolidated into forms appropriate for mining by performing summary or aggregation operations.
Data mining: an essential process where intelligent methods are applied to extract data patterns.
Pattern evaluation: to identify the truly interesting patterns representing knowledge based on interestingness measures.
Knowledge presentation: where visualization and knowledge representation techniques are used to present mined knowledge to users.
Data Cleaning
Data in the real-world is not available in proper(Many tuples might not have recorded attribute values).
Missing values may be due to
- Equipment failure.
- Inconsistent with other recorded data and thus deleted or misplaced.
- Data not entered correctly due to misunderstanding
- Certain data may not be considered important at the time of entry.
- Not register history or changes in the data.
Data Integration
Data integration: Combines data from multiple sources into a coherent store
- Schema integration: e.g., A.cust-id = B.cust-#
- Identify real-world entities from multiple data sources, e.g., Bill Clinton = William Clinton
- Detecting and resolving data value conflicts
- For the same real-world entity, attribute values from different sources are different
Possible reasons: different representations, different scales, e.g., metric vs. British units.
Price (dollars, euro), (kg, gram), total sales, etc.,
Price (dollars, euro), (kg, gram), total sales, etc.,
Handling Redundancy
Redundant data occur often when the integration of multiple databases is done.
- Object identification: The same attribute or object may have different names in different databases
- Derivable data: One attribute may be a “derived” attribute in another table, e.g., annual revenue
Redundant attributes can be detected by correlation analysis
Careful integration of the data from multiple sources may help reduce/avoid redundancies and inconsistencies and improve mining speed and quality
Data Transformation
Smoothing: remove noise from data
Aggregation: summarization, data cube construction
Generalization: concept hierarchy climbing
Normalization: scaled to fall within a small, specified range
- min-max normalization
- z-score normalization
- normalization by decimal scaling
Attribute/feature construction
- New attributes constructed from the given ones
Data Reduction Strategies
Dimensionality reduction: e.g., remove unimportant attributes
Data compression
Numerosity reduction: e.g., fit data into models
Discretization and concept hierarchy generation
Data Mining
- An essential process where intelligent methods are applied to extract data patterns
Pattern Evaluation
- To identify the truly interesting patterns representing knowledge based on interestingness measures.
Knowledge Presentation
- Where visualization and knowledge representation techniques are used to present mined knowledge to users
Applications of Data Mining
Customer Profiling: Data Mining helps to determine what kind of people buy what kind of products.
Identifying Customer Requirements: Data Mining helps in identifying the best products for different customers. It uses prediction to find the factors that may attract new customers.
Cross Market Analysis: Data Mining performs Association/correlations between product sales.
Target Marketing: Data Mining helps to find clusters of model customers who share the same characteristics such as interest, spending habits, income, etc
Determining Customer purchasing pattern: Data mining helps in determining customer purchasing pattern
Providing Summary Information: Data Mining provides us various multidimensional summary reports
Identifying Customer Requirements: Data Mining helps in identifying the best products for different customers. It uses prediction to find the factors that may attract new customers.
Cross Market Analysis: Data Mining performs Association/correlations between product sales.
Target Marketing: Data Mining helps to find clusters of model customers who share the same characteristics such as interest, spending habits, income, etc
Determining Customer purchasing pattern: Data mining helps in determining customer purchasing pattern
Providing Summary Information: Data Mining provides us various multidimensional summary reports
Finance Planning and Asset Evaluation: It involves cash flow analysis and prediction, contingent claim analysis to evaluate assets.
Resource Planning: It involves summarizing and comparing the resources and spending.
Competition: It involves monitoring competitors and market directions.
Resource Planning: It involves summarizing and comparing the resources and spending.
Competition: It involves monitoring competitors and market directions.
Major Issues of Data Mining
Mining Methodology- Mining different kinds of knowledge from diverse data types, e.g., bio, stream, Web
- Handling noise and incomplete data: data cleaning and data analysis methods that can handle noise are required. outlier mining methods for discovery and analysis of exceptional cases.
- Incorporation of background knowledge: domain knowledge is required to guide the discovery process and express patterns in concise terms and at different levels of abstraction.
User Interaction
- Data mining query languages and ad-hoc mining
- Data mining Query language needs to be developed to allow users to describe ad- hoc data mining tasks.
- Expression and visualization of data mining results
- Interactive mining of knowledge at multiple levels of abstraction.
Applications and Social Impacts
- Domain-specific data mining & invisible data mining Eg. Companies like Amazon keeps track of customer profiles
- Protection of data security, integrity, and privacy
- We need to observe data sensitivity and preserve people's privacy while performing successful data mining.
Summary
Data mining (knowledge discovery from data) is extracting or “mining” knowledge from a large amount of data.
Knowledge Discovery Process -> Data Cleaning, Data Integration, Data Selection, Data Transformation, Data Mining, Pattern Evaluation, Knowledge Presentation.
Knowledge Discovery Process -> Data Cleaning, Data Integration, Data Selection, Data Transformation, Data Mining, Pattern Evaluation, Knowledge Presentation.




{kind=link}
0 Comments